 Chapter 3, Lesson 1
Chapter 3, Lesson 1
Chapter 3, Lesson 1
Chapter 3, Lesson 1If you already know what a "link" is, and if you understand how the browser and server exchange information, you can skip this lesson.
The HTML hyperlink (or just 'link') is what makes the web page unique among documents. Many of us first observed the "clickable link" in the context of "help" files. In DOS and Windows help files, for example, clicking on a particular subject changed the screen to another document. In HTML, with the help of HTTP and the Internet, it suddenly became possible to "click" and gain access to a document halfway around the world, on a computer completely unknown to the operator. Further, it was a small step to enable the browser to accept an "image" file, and so produce (on screen) an image which appears to be part of a document. In most recent years, this functionality has been expanded to allow embedded sound and video files.
We will first deal with the use of clickable text links to provide access to local files, internet documents, and even specific parts of documents. Subsequent chapters will cover graphic links.
But what is a link? A link is a short text or graphic which points to another file (web page, or document) or to a virtual address on the Internet. In appearance, the text link is highlighted on the web page, usually by a unique color, and generally also by underlining. The text link actually contains two (2) parts: a hypertext reference and a description. In subsequent chapters, we'll see that the description may be replaced or augmented by a graphic image, but for now we concentrate on "just the text, ma'am".
The hypertext reference may take the form of a local file name, or an Internet address. You might say that the link points to that referenced file or address. The reference is usually hidden inside the HTML file. When the browser is first parsing the file, it makes an internal notation of the reference (i.e., it memorizes it). Then it shows the description on the screen, highlighting it in it's oh-so-nifty browser way, and quietly keeps track of it's location on the browser screen. When the link is activated by clicking on the description text, the browser responds appropriately.
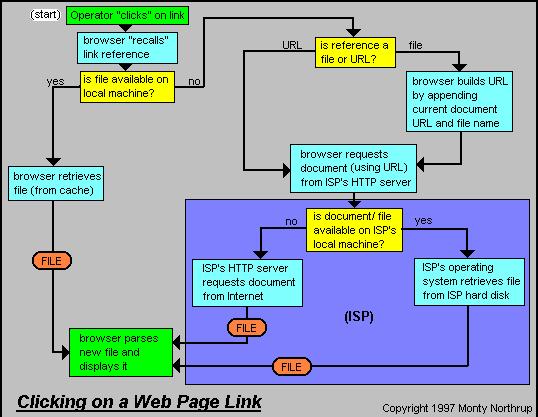
Now, let's stop pussy-footing around, and discuss how the browser responds when you "click" on a link. Recall how the browser, when it first loaded the web page file, stored the reference portion of the link? Well, when you click on it, the browser "recalls" the reference, because it needs to know what file to load, and where to go to get it. Then, it looks in the local cache storage to see if a copy of the requested file already exists locally. If it does, it immediately re-reads, parses, and displays it to the screen in the usual HTML manner.
Most of the time, however,the document requested by the link is not in local storage. This being the case, the browser now formulates a message which will be sent to the HTTP server on your ISP's computer. If the reference portion of the link is already a complete URL (which, for a web page begins with "http://"), then the browser simply includes that URL in its message request to the ISP's HTTP server. If, however, the reference portion of the link is a simple file name (for example, "myfile.html"), the browser builds a URL by taking the URL of the current document, removing the current document's file name, and appending the newly referenced filename. Once this is done, the browser has a complete URL, which it submits in a message to the ISP's HTTP server.
When the ISP's HTTP server receives the browser's message request, it determines what action and URL is requested, and responds accordingly. If the request is for a file or document outside its own jurisdiction, it forwards the message to the Internet. (Eventually, the message makes its way to the HTTP server who "owns" the requested file.) If, however, the request was for a document or file which resides in its own disk space, the ISP's computer retrieves it. Once the ISP's HTTP server has the requested file in hand (whether it came from the Internet or from local disk space), the file is transferred to the requesting browser. If, for some reason, the file is unavailable, the HTTP server returns an "error" to the browser. Finally (!) the browser has the file it requested when you clicked the link, and it can read, parse, and display the web page.
If you're still a little confused, don't worry about it too much. As we reveal the details of how to use links, it will become more and more obvious. For the visually inclined, there's a diagram ...here...
Sometimes an example can make more sense than an explanation. This whole process is imporant to understanding the use of links in HTML. Therefore, we'll run through an example, and hopefully make things crystal clear.
Here's an embedded link: Dumb Demo. (If you want, you can click on it to make sure I'm not pulling your leg). This link has two portions: the reference, and the description. The description is obvious: "Dumb Demo". The reference is embedded in the HTML file, and "remembered" by the browser. If you have an "advanced" graphical browser, such as Netscape, you can move the mouse cursor over the link (but without clicking), and somewhere on the screen you'll see the reference, in this case "demopage.htm".
If you had clicked on this link previously, and now you click on it again, the browser would simply recover the file from local cache storage, and re-display it (with hardly any waiting). But more than likely, because the link had not been previously loaded, the browser has more work to do. First, since the reference is a filename (not a complete URL), the browser proceeds to build one. It does this by taking the current pages' URL ("http://www.io.com/~maddog/html-for-real-people/c3_1.htm") and removing the filename ("c3_1.htm"). Then it appends the new reference ("demopage.htm") onto the shortened URL, thus formulating a complete URL: "http://www.io.com/~maddog/html-for-real-people/demopage.htm."
Now, the browser sends the completed URL in a request message to the ISP's HTTP server. The message basically says, "would you pretty-please send me the following file: http://www.io.com/~maddog/html-for-real-people/demopage.htm?" If your ISP happens to be 'io.com' (my ISP), then it would find the file you requested and return it to the browser, whereupon the browser would read, parse, and display the new web page. More likely, however, your ISP's HTTP server would forward your request to the Internet, and if everything works right, the request would end up at the www.io.com HTTP server (5 minutes later - ha! - sorry...). That server would then retrieve the file, returning it via your ISP's HTTP server to your browser, who then reads, parses, and displays the new web page. When you finally see the web page, you are dazzled, nay, stunned, and exclaim loudly, "Far out!"
If you're still a little befuddled, press on anyway. The most important thing to remember for now is that the HTML link consists of two parts, the reference and the description, and that together they point to another potential document. The rest will become more clear with hands-on experience.
{kind=link}